Deploying Faster Whisper on Kubernetes
Whisper is a popular open source Speech to text model created by OpenAI. In this tutorial, you will learn how to deploy Whisper on Kubernetes.
There are various implementations of Whisper available, but this tutorial will be using the Faster Whisper implementation and faster-whisper-server.
Deployment methods:
- K8s Deployment, a regular Kubernetes deployment and service.
- KubeAI, a project that provides private Open AI on K8s.
You can choose the method that best fits your needs. KubeAI also supports autoscaling and provides many other AI models out of the box that you can use. Scroll down to the bottom to see the KubeAI deployment method.
Prerequisites
You need to have a Kubernetes cluster running. If you don't have one yet, you can create one using kind or minikube.
Method 1: Using a regular Kubernetes deployment and service
Create a file called deployment.yaml with the following content:
apiVersion: apps/v1
kind: Deployment
metadata:
name: faster-whisper-server
spec:
replicas: 1
selector:
matchLabels:
app: faster-whisper-server
template:
metadata:
labels:
app: faster-whisper-server
spec:
containers:
- name: faster-whisper-server
image: fedirz/faster-whisper-server:latest-cpu
ports:
- containerPort: 8000
Note you can change the image to fedirz/faster-whisper-server:latest-gpu if you want to use the GPU version.
Create the deployment:
kubectl apply -f deployment.yaml
Next, we need to expose the deployment so we can access it from a stable endpoint.
Create a file called service.yaml with the following content:
apiVersion: v1
kind: Service
metadata:
name: faster-whisper-server
spec:
type: ClusterIP
selector:
app: faster-whisper-server
ports:
- protocol: TCP
port: 8000
targetPort: 8000
You can change the type to LoadBalancer if you want to expose the service to the internet.
To test the service, you can use kubectl port-forward to forward the service to your local machine.
kubectl port-forward service/faster-whisper-server 8000:8000
Now you can access the Web UI at http://localhost:8000.
It should look something like this:
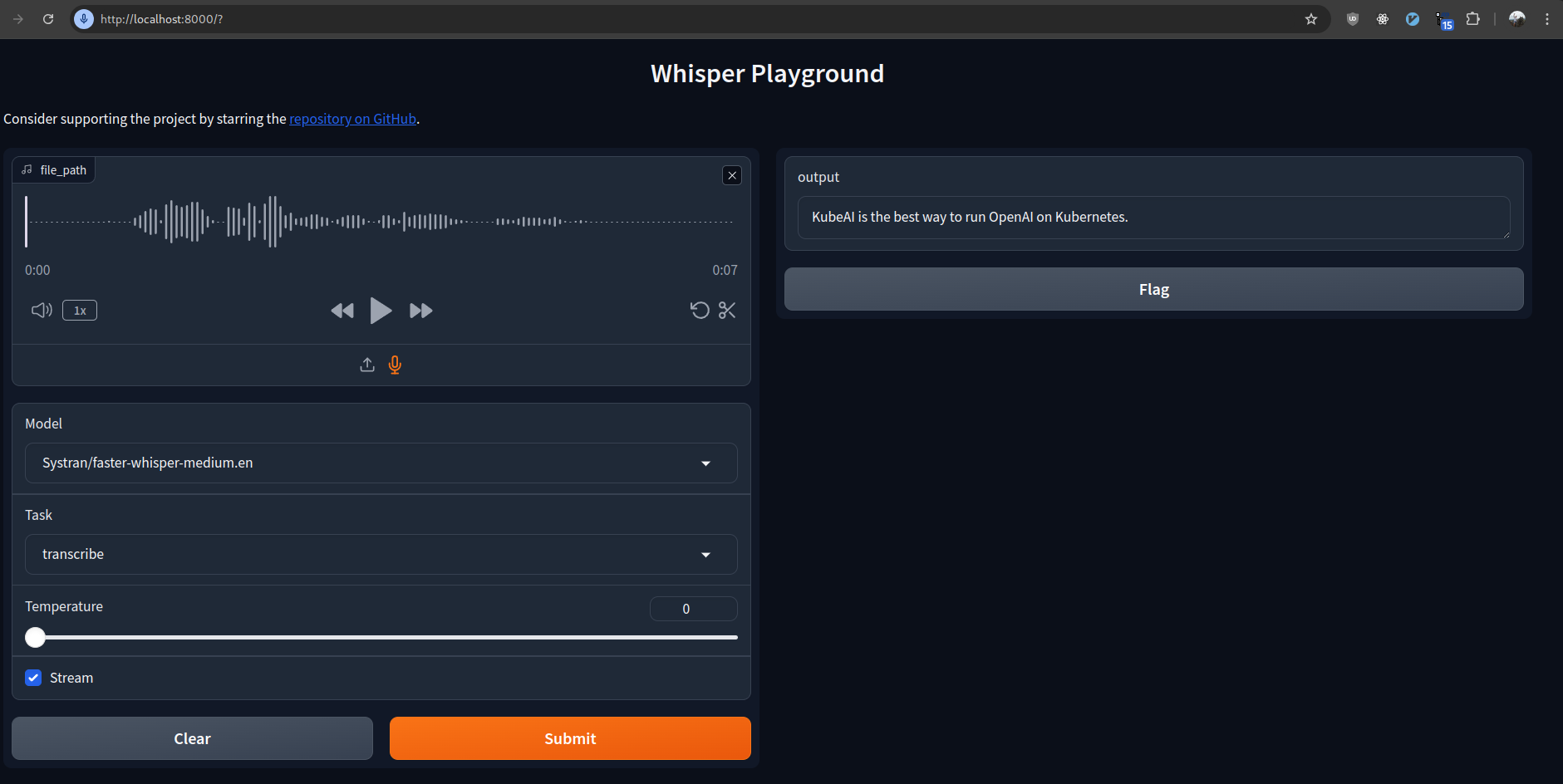
Faster Whisper Web UI
Method 2: Using KubeAI
KubeAI makes it easy to deploy AI models on Kubernetes. It provides an OpenAI compatible API endpoint and supports autoscaling.
Let's deploy Faster Whisper using KubeAI using Helm.
Create a file called helm-values.yaml with the following content:
models:
catalog:
faster-whisper-medium-en-cpu:
enabled: true
minReplicas: 1
Install KubeAI using the following command:
helm upgrade --install kubeai kubeai/kubeai \
-f ./helm-values.yaml \
--wait --timeout 10m
Verify that the faster-whisper pod is Ready:
kubectl get pods
You can access the OpenAI compatible API within the cluster at
http://kubeai//openai/v1/transcriptions.
For testing purposes, you can use kubectl port-forward to forward the service to your local machine.
kubectl port-forward service/kubeai 8000:80
Let's test the OpenAI compatible API using curl.
First, download some sample data. We're going to use the KubeAI intro video.
Download a sample video:
curl -L -o kubeai.mp4 https://github.com/user-attachments/assets/711d1279-6af9-4c6c-a052-e59e7730b757
Now test the OpenAI compatible API using curl:
curl http://localhost:8000/openai/v1/audio/transcriptions \
-F "file=@kubeai.mp4" \
-F "language=en" \
-F "model=faster-whisper-medium-en-cpu"
Note that the model name should match the model name in the helm-values.yaml file.
This is the response that I got back:
{"text":"Kube.ai, the open AI platform that runs on any Kubernetes cluster. It comes bundled with a local chat UI. Chat directly with any of the installed models. ScaleFromZero is supported out of the box without any additional dependencies. Notice how the quentool pod automatically gets created when we send the message. And finally, the user gets a valid response even though they had the ScaleFromZero."}
Need help with serving AI models on K8s? Take a look at the KubeAI project. It makes it easy to deploy ML models on K8s with an OpenAI compatible endpoint.