Deploying Mixtral on GKE with 2 x L4 GPUs
A100 and H100 GPUs are hard to get. They are also expensive. What if you could run Mixtral on just 2 x L4 24GB GPUs? The L4 GPUs are more attainable today (Feb 10, 2024) and are also cheaper. Learn how to easily deploy Mixtral on GKE with 2 x L4 GPUs in this blog post.
How much GPU memory is needed? Will it fit on 2 x L4?
For this post, we're using GPTQ quantization to load the model parameters in 4 bit. The estimated GPU memory when using 4bit GPTQ quantization would be:
A single L4 GPU has 24GB of GPU memory so 2 x L4 will have 48GB, which is more than enough to serve the Mixtral 7 * 8 billion parameter model. You can read the Calculating GPU memory for serving LLMs blog post for more information.
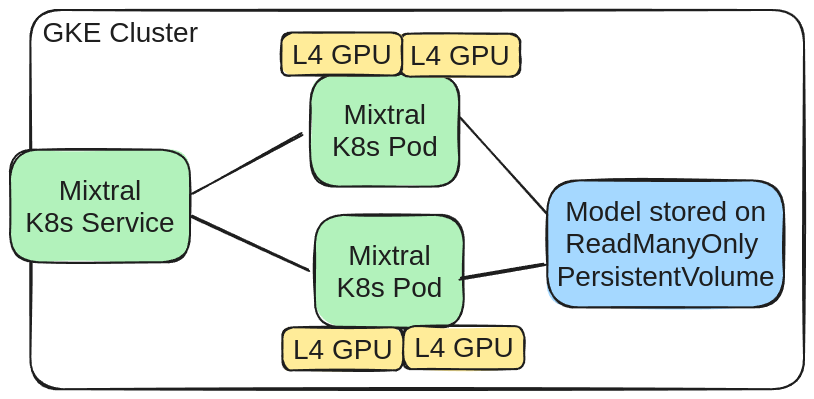
The post is structured in the following sections:
- Creating a GKE cluster with a spot L4 GPU node pool
- Downloading the model into a ReadManyOnly PVC
- Deploying Mixtral GPTQ using Helm and vLLM
- Trying out some prompts with Mixtral
Creating the GKE cluster
Create a cluster with a CPU nodepool for system services:
export CLUSTER_LOCATION=us-central1
export PROJECT_ID=$(gcloud config get-value project)
export CLUSTER_NAME=substratus
export NODEPOOL_ZONE=us-central1-a
gcloud container clusters create ${CLUSTER_NAME} --location ${CLUSTER_LOCATION} \
--machine-type e2-medium --num-nodes 1 --min-nodes 1 --max-nodes 5 \
--autoscaling-profile optimize-utilization --enable-autoscaling \
--node-locations ${NODEPOOL_ZONE} --workload-pool ${PROJECT_ID}.svc.id.goog \
--enable-image-streaming --enable-shielded-nodes --shielded-secure-boot \
--shielded-integrity-monitoring \
--addons GcsFuseCsiDriver
Create a GPU nodepool where each VM has 2 x L4 GPUs and uses Spot pricing:
gcloud container node-pools create g2-standard-24 \
--accelerator type=nvidia-l4,count=2,gpu-driver-version=latest \
--machine-type g2-standard-24 --ephemeral-storage-local-ssd=count=2 \
--spot --enable-autoscaling --enable-image-streaming \
--num-nodes=0 --min-nodes=0 --max-nodes=3 --cluster ${CLUSTER_NAME} \
--node-locations "${NODEPOOL_ZONE}" --location ${CLUSTER_LOCATION}
Downloading the model into a ReadManyOnly PVC
Downloading a 8 * 7 billion parameter model every time you launch an inference server takes a long time and will be expensive in egress costs. Instead, we'll download the model to a Persistent Volume Claim. That PVC will be used in ReadManyOnly mode across all the Mixtral serving instances.
Create a file named pvc.yaml with the following content:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mixtral-8x7b-instruct-gptq
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 30Gi
Create the PVC to store the model weights on:
kubectl apply -f pvc.yaml
The following Job will download the model to the PVC mixtral-8x7b-instruct-gptq using the Huggingface Hub API. The model is downloaded to the /model directory in the PVC. The revision parameter is set to gptq-4bit-32g-actorder_True to download the model with GPTQ quantization in 4 bit.
Create a file named load-model-job.yaml with the following content:
apiVersion: batch/v1
kind: Job
metadata:
name: load-model-job-mixtral-8x7b-instruct-gptq
spec:
template:
spec:
volumes:
- name: model
persistentVolumeClaim:
claimName: mixtral-8x7b-instruct-gptq
containers:
- name: model-loader
image: python:3.11
volumeMounts:
- mountPath: /model
name: model
command:
- /bin/bash
- -c
- |
pip install huggingface_hub
python3 - << EOF
from huggingface_hub import snapshot_download
model_id="TheBloke/Mixtral-8x7B-Instruct-v0.1-GPTQ"
snapshot_download(repo_id=model_id, local_dir="/model", cache_dir="/model",
local_dir_use_symlinks=False,
revision="gptq-4bit-32g-actorder_True")
EOF
restartPolicy: Never
Launch the load model Job:
kubectl apply -f load-model-job.yaml
You can watch the progress of the Job using the following command:
kubectl logs -f job/load-model-job-mixtral-8x7b-instruct-gptq
After a few minutes, the model will be downloaded to the PVC.
Deploying Mixtral using Helm
We are maintaining a Helm chart for vLLM. The Helm chart is available at Github substratusai/helm. We've also published a container image for vLLM that takes environment variables. The vLLM container image is available at Github substratusai/vllm-docker.
Install the Helm repo:
helm repo add substratusai https://substratusai.github.io/helm
helm repo update
Create a file named values.yaml with the following content:
model: /model
servedModelName: mixtral-8x7b-instruct-gptq
readManyPVC:
enabled: true
sourcePVC: "mixtral-8x7b-instruct-gptq"
mountPath: /model
size: 30Gi
quantization: gptq
dtype: half
maxModelLen: 8192
gpuMemoryUtilization: "0.8"
resources:
limits:
nvidia.com/gpu: 2
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
replicaCount: 1
Notice that we're specifying a readManyPVC with the sourcePVC set to mixtral-8x7b-instruct-gptq, which we created in the previous step.
The mountPath is set to /model and model parameter for vLLM points to that local path.
The quantization parameter is set to gptq and the dtype parameter is set to half. Setting it to half is required for GPTQ quantization.
The gpuMemoryUtilization is set to 0.8, because otherwise you will get an out of GPU memory error.
The replicaCount is set to 1 and so the moment you install the Helm chart, the deployment will start with 1 pod.
Looking for an autoscaling Mixtral deployment that supports scale from 0? Take a look at Lingo: ML Proxy and autoscaler for K8s.
Install the Helm chart:
helm install mixtral-8x7b-instruct-gptq substratusai/vllm -f values.yaml
After a while you can check whether pods are running:
kubectl get pods
Once the pods are running, check logs of the deployment pods:
kubectl logs -f deployment/mixtral-8x7b-instruct-gptq
Sent some prompts to Mixtral
A K8s Service of type ClusterIP named mixtral-instruct-gptq-vllm was created by the Helm chart.
The Service by default is only accessible from within the cluster. You can use kubectl port-forward to forward the Service to your local machine.
kubectl port-forward service/mixtral-8x7b-instruct-gptq-vllm 8080:80
Sent a prompt to the Mixtral model using the following command:
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{"model": "mixtral-8x7b-instruct-gptq", "prompt": "<s>[INST]Who was the first president of the United States?[/INST]", "max_tokens": 40}'
Got more questions? Don't hesitate to join our Discord and ask away.