Learn how to benchmark vLLM to optimize for speed
Looking to deploy vLLM on Kubernetes? Check out KubeAI, providing private Open AI on Kubernetes.
Learn to benchmark vLLM so you can optimize the performance of your models. My experience has been that the performance can improve up to 20x depending on the configuration and use case. So learning to benchmark is crucial.
vLLM provides a simple benchmarking script that can be used to measure the performance of serving using the OpenAI API. It also supports other backends, but for this blog post we will focus on the OpenAI API.
The benchmarking script is available here.
For this tutorial, we will deploy vLLM on a Kubernetes cluster using the vLLM helm chart. We can then run the benchmark from within the vLLM container to ensure that the benchmark is as accurate as possible.
Deploying Llama 3.1 8B Instruct in FP8 mode
This assumes you have a K8s cluster with at least a single 24GB GPU available.
Run the following command to deploy vLLM:
helm upgrade --install llama-3-1-8b-instruct substratusai/vllm -f - <<EOF
model: neuralmagic/Meta-Llama-3.1-8B-Instruct-FP8
gpuMemoryUtilization: "0.90"
maxModelLen: 16384
image:
tag: v0.5.3.post1
env:
- name: EXTRA_ARGS
value: --kv-cache-dtype=auto --enable-prefix-caching --max-num-batched-tokens=16384
resources:
limits:
nvidia.com/gpu: "1"
EOF
After a few minutes the pod should report Running and you can proceed to the next step.
Running the benchmark
First get an interactive shell in the vLLM container:
kubectl exec -it $(kubectl get pods -l app.kubernetes.io/instance=llama-3-1-8b-instruct -o name) -- bash
Now that you are in the container itself, download the benchmark script:
git clone https://github.com/vllm-project/vllm.git
git checkout 16a1cc9bb2b4bba82d78f329e5a89b44a5523ac8
cd vllm/benchmarks
The easiest way to run the benchmark is to use the random dataset. However, this dataset may not be representative of your use case.
You can now run the benchmark using the following command:
python3 benchmark_serving.py --backend openai \
--base-url http://127.0.0.1:8080 \
--dataset-name=random \
--model neuralmagic/Meta-Llama-3.1-8B-Instruct-FP8 \
--seed 12345
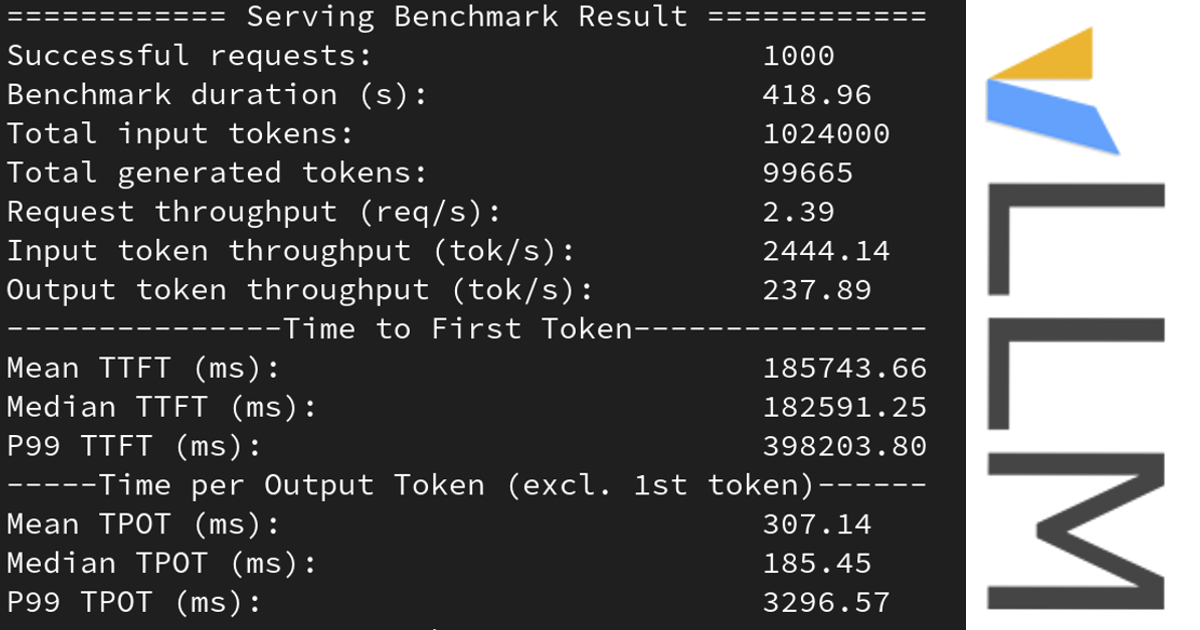
This was the output I got when running the benchmark on an L4 GPU:
Namespace(backend='openai', base_url='http://127.0.0.1:8080', host='localhost', port=8000, endpoint='/v1/completions', dataset=None, dataset_name='random', dataset_path=None, model='neuralmagic/Meta-Llama-3.1-8B-Instruct-FP8', tokenizer=None, best_of=1, use_beam_search=False, num_prompts=1000, sharegpt_output_len=None, sonnet_input_len=550, sonnet_output_len=150, sonnet_prefix_len=200, random_input_len=1024, random_output_len=128, random_range_ratio=1.0, request_rate=inf, seed=12345, trust_remote_code=False, disable_tqdm=False, save_result=False, metadata=None, result_dir=None, result_filename=None)
Starting initial single prompt test run...
Initial test run completed. Starting main benchmark run...
Traffic request rate: inf
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 460.12
Total input tokens: 1024000
Total generated tokens: 97886
Request throughput (req/s): 2.17
Input token throughput (tok/s): 2225.51
Output token throughput (tok/s): 212.74
---------------Time to First Token----------------
Mean TTFT (ms): 204348.97
Median TTFT (ms): 199900.52
P99 TTFT (ms): 437925.01
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 311.95
Median TPOT (ms): 169.56
P99 TPOT (ms): 2874.86
---------------Inter-token Latency----------------
Mean ITL (ms): 2803.83
Median ITL (ms): 101.32
P99 ITL (ms): 50446.18
==================================================
Conclusion
You now learned the basics of benchmarking vLLM using the random dataset. You can also use the ShareGPT dataset to benchmark on a more realistic dataset.
Looking for help in optimizing vLLM performance? Shoot us an email at
founders@substratus.ai
Extra: Full list of options of vLLM benchmark script
For a full list of options, you can run:
python3 benchmark_serving.py --help
usage: benchmark_serving.py [-h]
[--backend {tgi,vllm,lmdeploy,deepspeed-mii,openai,openai-chat,tensorrt-llm,scalellm}]
[--base-url BASE_URL] [--host HOST] [--port PORT] [--endpoint ENDPOINT]
[--dataset DATASET] [--dataset-name {sharegpt,sonnet,random}]
[--dataset-path DATASET_PATH] --model MODEL [--tokenizer TOKENIZER]
[--best-of BEST_OF] [--use-beam-search] [--num-prompts NUM_PROMPTS]
[--sharegpt-output-len SHAREGPT_OUTPUT_LEN] [--sonnet-input-len SONNET_INPUT_LEN]
[--sonnet-output-len SONNET_OUTPUT_LEN] [--sonnet-prefix-len SONNET_PREFIX_LEN]
[--random-input-len RANDOM_INPUT_LEN] [--random-output-len RANDOM_OUTPUT_LEN]
[--random-range-ratio RANDOM_RANGE_RATIO] [--request-rate REQUEST_RATE]
[--seed SEED] [--trust-remote-code] [--disable-tqdm] [--save-result]
[--metadata [KEY=VALUE ...]] [--result-dir RESULT_DIR]
[--result-filename RESULT_FILENAME]
Benchmark the online serving throughput.
options:
-h, --help show this help message and exit
--backend {tgi,vllm,lmdeploy,deepspeed-mii,openai,openai-chat,tensorrt-llm,scalellm}
--base-url BASE_URL Server or API base url if not using http host and port.
--host HOST
--port PORT
--endpoint ENDPOINT API endpoint.
--dataset DATASET Path to the ShareGPT dataset, will be deprecated in the next release.
--dataset-name {sharegpt,sonnet,random}
Name of the dataset to benchmark on.
--dataset-path DATASET_PATH
Path to the dataset.
--model MODEL Name of the model.
--tokenizer TOKENIZER
Name or path of the tokenizer, if not using the default tokenizer.
--best-of BEST_OF Generates `best_of` sequences per prompt and returns the best one.
--use-beam-search
--num-prompts NUM_PROMPTS
Number of prompts to process.
--sharegpt-output-len SHAREGPT_OUTPUT_LEN
Output length for each request. Overrides the output length from the ShareGPT dataset.
--sonnet-input-len SONNET_INPUT_LEN
Number of input tokens per request, used only for sonnet dataset.
--sonnet-output-len SONNET_OUTPUT_LEN
Number of output tokens per request, used only for sonnet dataset.
--sonnet-prefix-len SONNET_PREFIX_LEN
Number of prefix tokens per request, used only for sonnet dataset.
--random-input-len RANDOM_INPUT_LEN
Number of input tokens per request, used only for random sampling.
--random-output-len RANDOM_OUTPUT_LEN
Number of output tokens per request, used only for random sampling.
--random-range-ratio RANDOM_RANGE_RATIO
Range of sampled ratio of input/output length, used only for random sampling.
--request-rate REQUEST_RATE
Number of requests per second. If this is inf, then all the requests are sent at time
0. Otherwise, we use Poisson process to synthesize the request arrival times.
--seed SEED
--trust-remote-code Trust remote code from huggingface
--disable-tqdm Specify to disable tqdm progress bar.
--save-result Specify to save benchmark results to a json file
--metadata [KEY=VALUE ...]
Key-value pairs (e.g, --metadata version=0.3.3 tp=1) for metadata of this run to be
saved in the result JSON file for record keeping purposes.
--result-dir RESULT_DIR
Specify directory to save benchmark json results.If not specified, results are saved
in the current directory.
--result-filename RESULT_FILENAME
Specify the filename to save benchmark json results.If not specified, results will be
saved in {backend}-{args.request_rate}qps-{base_model_id}-{current_dt}.json format.