Improving LLM Serving Performance by 34% with Prefix Cache aware load balancing
Prefix Cache aware load balancing improves the performance of the Llama 3.1 7B model by 34% when deployed on two replicas, each utilizing an L4 GPU. This blog post provides insights into the benchmarking setup, results, and the mechanics of Prefix Cache aware load balancing.
What is Prefix Caching?
Inferencing engines like vLLM support Prefix Caching to optimize performance when multiple requests share the same prompt prefix. By caching tokenized prefixes, these engines avoid redundant computations, resulting in significant efficiency gains for prompt-heavy applications.
Why Use Prefix Cache Aware Load Balancing?
When deploying multiple replicas of a model, ensuring requests with shared prefixes are directed to replicas with cached prefixes becomes critical. Prefix Cache aware load balancing addresses this by intelligently routing such requests, reducing computational overhead and latency.
For instance, consider an environment with eight replicas of a model. Without cache-aware load balancing, requests are evenly distributed, disregarding prefix locality. This leads to redundant caching across replicas. In contrast, Prefix Cache aware load balancing ensures cached prefixes are reused, saving time and resources.
At the time of writing, KubeAI is the only AI serving platform supporting Prefix Cache aware load balancing.
Benchmarking Results
To quantify the benefits, we benchmarked Prefix Cache aware load balancing against traditional least-load-based balancing under two scenarios:
- Scenario 1: Two replicas serving the Llama 3.1 7B model on L4 GPUs.
- Scenario 2: Eight replicas serving the Llama 3.1 70B model on H100 GPUs.
The ShareGPT dataset was used, focusing on conversations with at least five messages and over 2,500 characters.
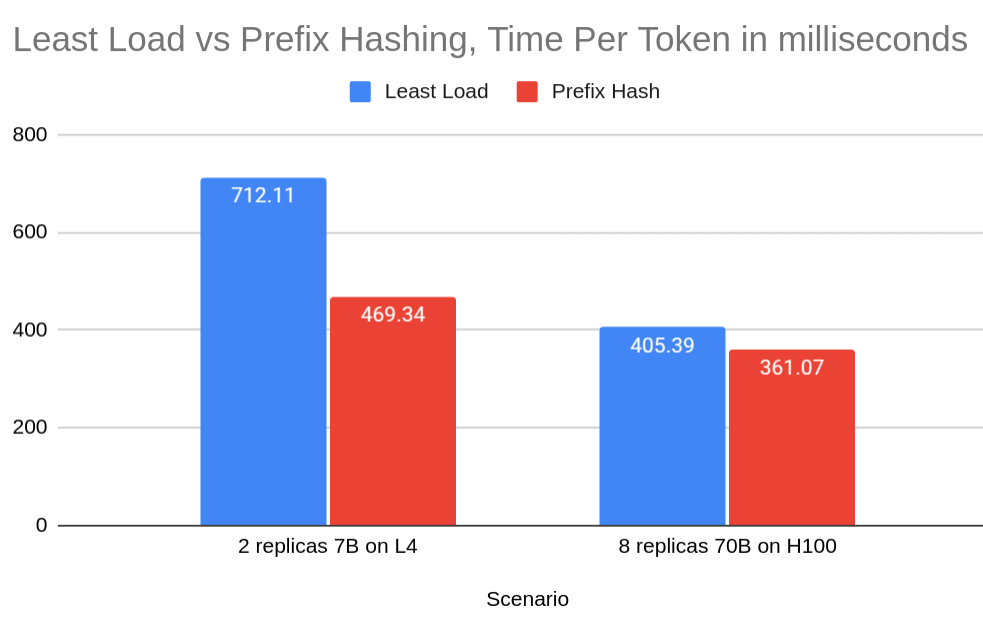
Scenario 1: Two Replicas with Llama 3.1 7B on L4 GPUs
Results demonstrated a 34% reduction in average token processing time, from 712.11ms (Least Load) to 469.34ms (Prefix Cache).
Steps to reproduce and full results are available here.
Scenario 2: Eight Replicas with Llama 3.1 70B on H100 GPUs
In this configuration, we observed a 12% reduction in average token processing time, from 405.39ms (Least Load) to 361.07ms (Prefix Cache).
Details on this setup and results can be found here.
Conclusion
Prefix Cache aware load balancing delivers substantial performance improvements, with up to a 34% reduction in token processing time for smaller models and notable gains for larger configurations. This approach is particularly advantageous for serving environments with high request concurrency and shared prompts.
By incorporating Prefix Cache aware load balancing, AI serving platforms can significantly enhance efficiency, making it an essential optimization for large-scale deployments.